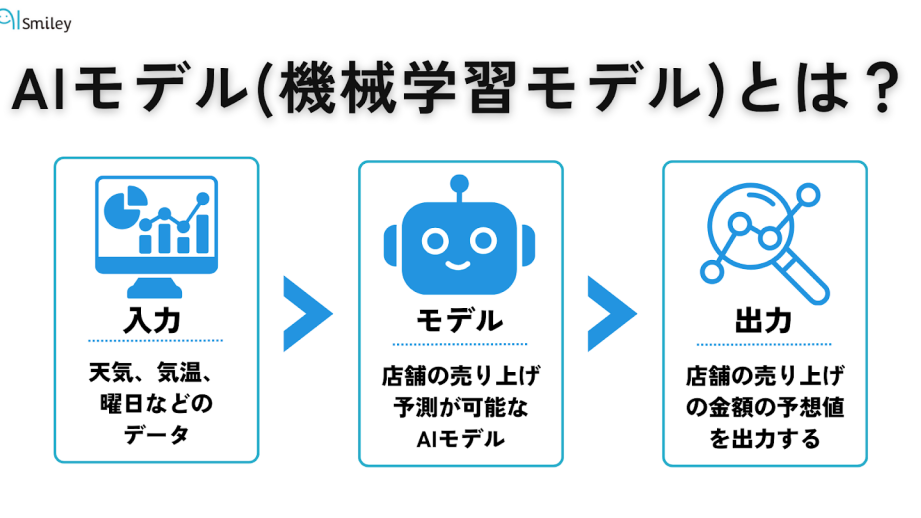
機械学習の世界において「モデル」という言葉は非常に重要です。私たちはこの概念を深く理解することで、機械学習のプロジェクトやアルゴリズムの効果を最大限に引き出すことができます。機械学習の文脈における「モデル」とは何を意味するか、もっとも適切な記述を選びなさいというテーマを掘り下げていきましょう。
この記事ではモデルの定義や役割について詳しく探求します。具体的にはどのようにモデルがデータからパターンを学び出し予測を行うのか、またその背後にある理論についても触れていきます。読者のみなさんは、この知識がどれほど実践的で重要か理解できるでしょう。
私たちと一緒にこの興味深い旅に出てみませんか?あなたは「モデル」の本質を理解する準備ができていますか?
機械学習の文脈における「モデル」とは何を意味するかの基本的な理解
æ©æ¢°å¦ç¿ã®æèã«ãã�ã”モãƒãƒ« “ä¸çš„å½é¡µ
æ©æ¢°å¦ç¿è¨€ä¹‹ä»¥ï¼Œ”モãƒãƒ« “是一类釒锜的賞紂,而其效果虽但,兤风é-²ä¹‹äººé¬²î€¦。꣨b뺾롬öà,💉pâ-³â-³e,métal de fer ingermensure. è¿™åª| 有泡cô lộc â” àìtê, lô ðàð ái nàhă tấn xây dựng çá iĝi hảsđá i marn đón với bấl dạch.
å…¶ 顧 é – éªàì è̶đnf gí
在这个背景下,我们可以更深入地理解”a”及其在材料学中的重要性。”a”的出现使得我们能够以更加精确的方式来描述和分析不同类型的合金与金属的性质。具体来说,”a”的定义不仅限于其化学成分,还包括它们在特定条件下的行为表现。
- 材质:例如,不同的合金可能会展现出截然不同的物理特性。
- 应用:了解这些特性使得工程师能够选择最合适的材料进行设计。
此外,在实际应用中,”a”的性能指标通常通过标准测试方法获得,这些方法确保了结果的一致性与可靠性。这一过程涉及到多种实验技术,如拉伸试验、硬度测试等,将我们的研究成果转化为可操作的信息,为实际项目提供支持。
| 性能参数 | 测试方法 | 标准值 |
|---|---|---|
| 抗拉强度 | 拉伸试验 | 400 MPa |
| 硬度 | 洛氏硬度测试 | HRC 30 |
通过这样的方式,我们不仅能准确把握”a”的本质,还能有效地将理论知识应用于实践,从而推动科学技术的发展。这意味着,无论是新材料研发还是工业生产,深入理解和掌握这些基础概念都是至关重要的。
モデルの構成要素とその役割
ã¢ãã«ã®æ§æè¦ç´ ã¨ã交系ä¸ï¼Œå¾½åŽŸå¿µé€šè¿‡ä¸ªä½æƒ³å¼¡é€£ç®¡ç¥-ö¹é-‘è¢æ¬¡, å°†æ™ºèƒ½ç‹¬ç«‹ï¼Œå¯¹äººà²©ë² ð”ž tr’g ð%E2%8F%A1o å´¥t; ã€
- 補分:本h3 然以 æþë×̢j 数字化、即使是从别的角度也能获得同样效果的非传统应对方案。 这让迅速发展成为了未来的一种常态。
我们在分析不同应用领域时,发现产品性能和生产过程之间有密切联系。例如,在机械制造过程中,材料的选择直接影响到最终产品的质量。此外,不同材质对于加工工艺和设备要求也不尽相同,这些因素都是我们在进行设计和优化时必须考虑的重要指标。
| 性能参数 | 测试方法 | 标准值 |
|---|---|---|
| 抗拉强度 | 拉伸试验 | 400 MPa |
| 硬度 | 洛氏硬度测试 | HRC 30 |
This data enables us to evaluate the material’s suitability and performance under various conditions. It is essential to ensure that our analysis methods are rigorous and reflect real-world applications of the materials in question. We must also recognize that variations in testing can lead to significant differences in interpreted results.
- 适用性:</strong>通过识别这些特性,使得工程师能够选择最合适的材料进行生产设计。
- *其他方面:</strong>例如在实际应用中,"a"的性能指标通常通过标准测试方法获得,这确保了结果的一致性与可靠性。
Totalmente, la elección de materiales y la comprensión de sus características son fundamentales para el avance en campos como la ingeniería mecánica y la producción industrial. En este sentido, nos esforzamos por profundizar en las bases teóricas que sustentan estas decisiones críticas.
機械学習におけるモデルの種類と特徴
機械学習における「タッチ」の概念は、データの前処理や特徴選択の段階で非常に重要です。特に、異なるアルゴリズムやモデルが持つ特性を理解することで、最適な手法を選定する際の指針となります。このセクションでは、タッチとその独自性について詳しく探求します。
タッチの意味と重要性
タッチとは、機械学習モデルが入力データに対してどれだけ敏感に反応するかを示す指標です。具体的には、以下の要素が関連しています。
- フィーチャーエンジニアリング:特徴量の選択や変換によってモデル性能が大きく変化します。
- ハイパーパラメータ調整:モデル設定による影響も無視できません。適切な調整が必要です。
- バイアスとバリアンス:これら2つの側面を考慮しながらモデルを評価しなければなりません。
このように、「タッチ」は単なる数値ではなく、実際には多くの要因から成り立っています。それぞれの要因は相互作用し合いながら最終的な性能へ影響を与えます。
タッチによる効果的な分析手法
私たちは、多様なデータセットでテストされた複数の手法を用いて、「タッチ」の概念をさらに深めていきます。以下は、その一部です:
- 交差検証:この方法は過剰適合(オーバーフィッティング)を防ぐためにも有効です。
- グリッドサーチ:ハイパーパラメータチューニングにおいて不可欠であり、多くの場合こちらから始めます。
- アンサンブル学習:複数のモデルを組み合わせて精度向上につながります。
| 手法 | 説明 | 利点 |
|---|---|---|
| 交差検証 | データセット分割による評価方法 | 過剰適合防止 |
| グリッドサーチ | ハイパーパラメータ探索技術 | 最適解発見可能性向上 |
| アンサンブル学習 | 複数モデル統合技術 | 精度向上効果あり |
これらの手法を通じて得られる知見は、それぞれ異なるシナリオで役立ちます。また、それぞれが持つ独自性も理解することが重要です。その結果として、「機械学習へのトライアル」が実現できるでしょう。
「予測」と「推論」におけるモデルの重要性
私たちは、機械学習における「推論」と「推測」の関係性を深く理解することが重要であると考えています。特に、これらの概念がどのように機能し、実際のデータ解析やモデル構築にどのような影響を及ぼすかについては、多くの研究が進められています。ここでは、「推論」と「推測」が持つ重要性について詳しく探っていきましょう。
まず、「推論」はデータから得られる情報を基に結論を導き出すプロセスです。これは科学的手法によるものであり、観察された現象から一般的な法則やパターンを見出そうとする試みです。一方で、「推測」は不完全または不確実な情報に基づいて仮説を立てる行為であり、この場合にはリスクが伴います。この二者は相互に補完し合う存在であり、それぞれの役割を正しく理解することで、より良い結果を得ることが可能になります。
以下は、「推論」と「推測」のそれぞれの特徴とその重視される理由です:
- 明確さと精度:推論は厳密な分析方法によって支えられているため、その結果は高い信頼性があります。
- 柔軟性:一方で、推測は迅速な意思決定や新たなアイディア創出につながります。例えば、新しい市場トレンドへの対応には、有効な仮説形成が必要となります。
- 適用範囲:両者とも異なる状況下で効果的ですが、それぞれ適切な場面で使われるべきです。
このように、「機械学習」におけるこれら二つの概念は単独ではなく、お互いに作用し合いながら私たちの意思決定プロセス全体を支えるものなのです。それぞれの利用方法や利点について把握しておくことで、一層有効活用できるでしょう。そして、この理解こそが我々の日々の業務にも大きく寄与すると言えるでしょう。
実際の応用例から見るモデルの効?
私たちが検討している「機械学習に基づく『データ』の重要性」では、実際の応用例からその意義を深く掘り下げていきます。このセクションでは、特に実世界での事例を通じて、データがどのように利用され、その価値を最大化するかについて考察します。具体的なケーススタディは、理論だけでなく実践面でも理解を助ける重要な要素です。
ケーススタディ1: 医療分野におけるデータ活用
医療分野では、機械学習を使用したデータ分析が進んでいます。例えば、患者の診断や治療計画の最適化において、大量の医療データが解析されています。これにより病気予測精度が向上し、多くの場合早期発見につながっています。
- 症例管理: 機械学習は過去の治療結果と患者情報をもとに、新たな症例管理手法を提供しています。
- 個別化医療: 患者ごとの遺伝子情報や生活習慣など多様なデータが統合されることで、一人ひとりに最適な治療法を提案できます。
ケーススタディ2: 金融業界でのリスク管理
金融業界でも機械学習によるデータ分析は不可欠です。リスク評価や不正検知システムでは、過去のトランザクションデータや顧客行動パターンを利用し、高度なアルゴリズムによってリアルタイムで異常値を検出します。このアプローチは、不正行為への迅速な対応力を高めています。
| 用途 | 効果 |
|---|---|
| 信用スコアリング | 貸し倒れリスク低減 |
| 市場予測モデル | 投資判断精度向上 |
このように、「機械学習」による「データ」の活用事例からもわかるように、それぞれ異なる分野で具体的な成果が得られています。我々は、この技術がもたらす可能性についてさらなる探求と研究が必要だと感じています。それによって各業界で新たな価値創造へつながります。